intrinsics.yml
裡面有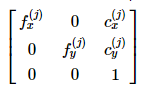
camera_left,或是說第一個相機的相機矩陣,M1。
而D1則是他的畸變參數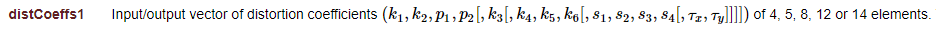
同理M2、D2則是camera_right,第二個相機的相機矩陣與畸變參數
extrinsics.yml
裡面則有透過我們一開始假設在虛擬世界座標,有一個棋盤格,
透過左邊相機的特徵影像角點使用solvePnP的方式對這個棋盤求解求解3D-2D之間的位置。
我可以得到相對於世界座標原點,第一個相機的R1|t1
同樣的方法我可以求得第二個相機的R2|t2
當我有第一個相機的位置和第二個相機的位置,我就可以求得兩個相機之間的轉換方式R|T。
而再stereoCalibrate我可以得到兩台相機的相機參數與畸變參數和兩台相機之間的R|T,
我再透過stereoRectify得到extrinsics後面五個參數
首先是改正後兩台相機的旋轉,我不確定這裡的旋轉
跟stereoCalibrate內部第一次求解的solvePnP所得到的R1、R2可能有甚麼不一樣的差別?
也許改正後會影響特徵點的影像角點,進而導致第一次求解的solvePnP可能精度不高。
再來則是兩台相機的投影矩陣,未來應該可以透過這個兩個矩陣使用triangulatePoints()
算出特徵匹配點的3D座標。(可能會在日後的內容實際做這個練習)
而Q矩陣的部分則是深度映射矩陣,可以將帶有深度(視差)的影像,轉換成3D座標透過
reprojectImageTo3D()這個方法。
最後我比較了單目校正與雙目深度校正,其左邊相機的相機矩陣與畸變參數,
兩種方法得出的相機參數不太一樣,
有可能是再讀image_list的時候,單目因為沒有右邊影像的關係,14組影像都會加入優化。
而在深度校正的部分,我輸入了14組影像卻只抓到了12組pairs。
而我原本以為streoCalib 可能角度精度影響的緣故,但校正程式裡面也有去做cornerSubPix。
可能是除了使單個相機的再投影誤差最小,兩個相機間的核線約束關係使得streoCalib的結果有些差異。
而flags=預設的 CALIB_FIX_INTRINSIC,似乎會將輸入的內參數當作其他方法得到的校正參數,而不會加進目標涵式進行優化。
而在範例程式內的Flags =CALIB_USE_INTRINSIC_GUESS,則是將輸入的值做為初始值進行優化,而如果你有做過機器學習的經驗,初始值的好壞,可能會影響程式最終結果的表現。也許個別校正之後再輸入到streoCalib,做初始值優化,甚至固定初始值只讓streoCalib去求相機之間的旋轉,其結果可能比較精準?有興趣的朋友歡迎多加嘗試。

